原标题:《Group and Attack: Auditing Differential Privacy》
发表平台:CCS ’23, November 26–30, 2023, Copenhagen, Denmark
摘要
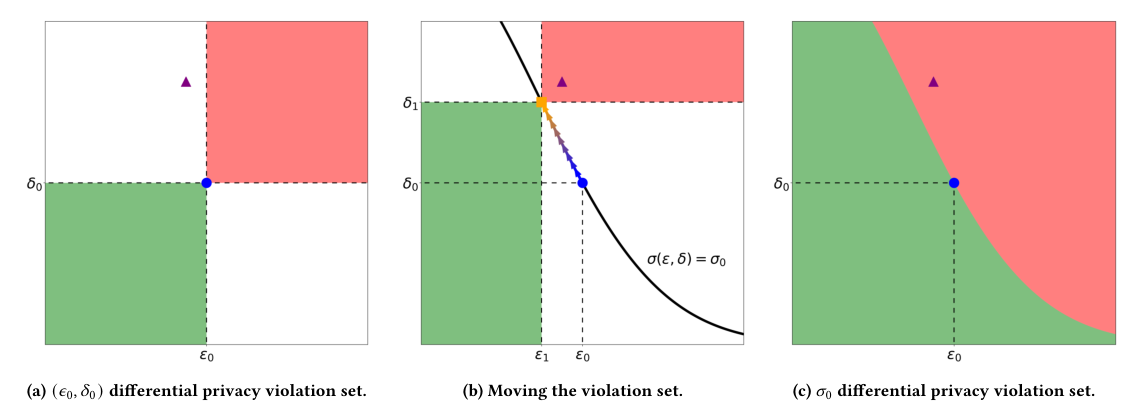
本文介绍了一种新的差分隐私审计方法“Group and Attack”,该方法能够有效地发现差分隐私算法中的违规行为。通过将许多产生相同算法的(ε, δ)参数对归类在一起,这种方法在搜索违规行为时更加高效和精确。实验结果表明,“Group and Attack”能够在多个最先进的差分隐私算法中发现之前未知的漏洞,并且在84%的情况下优于现有的审计工具。此外,该方法还能帮助识别漏洞的根本原因,这是其他差分隐私测试工具目前无法做到的。
解决的主要问题
本文主要研究领域为差分隐私算法的审计。随着差分隐私技术在私人机器学习应用中的广泛应用,其实现中常常存在细微的漏洞,这些漏洞可能导致隐私泄露。然而,现有的差分隐私审计工具通常直接扩展自ε-差分隐私工具,通过固定ε或δ来搜索违规行为,这限制了它们高效发现(ε, δ)差分隐私违规行为的能力。本文旨在开发一种新的审计方法,以克服这一限制,提高审计效率和准确性。
原标题《Privacy and Fairness in Federated Learning: on the Perspective of Trade-off》
发表平台:ACM Computing Surveys
摘要
本文综述了联邦学习(FL)中的隐私与公平性问题,并探讨了两者之间的相互作用。尽管在保护隐私或确保结果公平方面已经取得了显著进展,但这两者之间的平衡仍然是一个相对较少研究的领域。文章不仅回顾了现有的解决方案,还分析了联邦学习中独特的挑战,并提出了未来的研究方向,以期实现既保护隐私又保证公平性的联邦学习系统。
解决的主要问题
本文主要关注联邦学习领域的隐私与公平性问题。随着大数据时代的到来,如何在利用大量数据训练机器学习模型的同时保护个人隐私成为了一个重要的研究课题。此外,确保算法输出的公平性也是社会广泛关注的问题之一。本文探讨了在追求隐私保护和结果公平的过程中可能产生的冲突和权衡,指出单一考虑其中一个方面可能会对另一个方面造成不利影响,从而提出了需要同时考虑这两个方面的观点。
原标题:《AnonPSI: An Anonymity Assessment Framework for PSI 》
发表平台:Network and Distributed System Security (NDSS) Symposium 2024
摘要
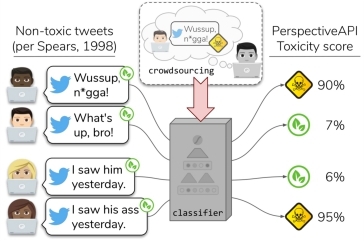
本文提出了一个针对私有集合交集(PSI)协议的匿名性评估框架AnonPSI。研究发现,尽管PSI协议广泛应用于安全地计算两个数据集交集的功能,但其容易受到集合成员推理攻击(SMIA)的影响,即使是最严格的仅返回交集基数的PSI版本也不例外。文章首先指出了现有工作在衡量隐私泄露方面的不足,并提出了两种改进的攻击策略:确定性和统计性策略。同时,文章展示了如何利用辅助信息(如交集成员的负载总和PSI-SUM)增强攻击效率。通过对两个真实数据集的全面测试,证明了所提方法在提高攻击效率方面明显优于先前的研究成果。这表明单独依赖现有的PSI协议可能无法提供足够的隐私保障,建议综合运用其他隐私增强技术来进一步强化隐私保护。
原标题《Enc2:Privacy-Preserving Inference for Tiny IoTs via Encoding and Encryption》
发表平台:ACM MobiCom ‘23
摘要
本文介绍了名为Orient的新框架,该框架旨在为资源受限的小型物联网设备提供一种轻量级的隐私保护机器学习方法。通过结合编码和加密技术,Orient在保证数据隐私的同时显著降低了推断延迟,并且消除了对边缘设备进行编码的需求。实验结果显示,Orient相比现有的隐私保护方法,在执行复杂的深度学习任务如目标检测和图像分类时,能够提供更好的性能和更高的隐私保护水平。
原标题:《CTAB-GAN+: enhancing tabular data synthesis》
发表平台:Frontiers in Big Data
摘要
本文介绍了一种新的条件表格生成对抗网络(CTAB-GAN+),旨在生成高质量的合成数据,同时提供严格的隐私保护。CTAB-GAN+通过添加下游损失来提高合成数据的效用,使用Wasserstein损失和梯度惩罚来改善训练收敛性,并引入了针对混合连续-分类变量和不平衡数据的新编码器。此外,CTAB-GAN+使用差分隐私随机梯度下降(DP-SGD)进行训练,以确保隐私保护。实验结果表明,CTAB-GAN+在多个数据集和学习任务中,能够在给定的隐私预算下,将机器学习效用(如F1分数)提高至少21.9%。

在数据隐私日益重要的今天,如何在保护数据隐私的前提下进行数据交集操作成为了学术界和工业界共同关注的焦点。其中,两方私有集合交集(Private Set Intersection, PSI)作为一种重要的密码学应用,允许两个参与方在不知道对方完整集合的情况下,共同计算出双方集合的交集。本文将深入解读由梁之源等人撰写的论文《Benchmark of Two-party Private Set Intersection》,探讨PSI的基本概念、技术原理、应用场景以及最新进展。
一、PSI的基本概念
PSI的核心目标是允许两个参与方(通常称为发送方和接收方)在保护各自数据隐私的前提下,共同计算出它们集合的交集。在这个过程中,双方均不会了解到交集之外的其他信息。这种隐私保护特性使得PSI在许多场景中都具有广泛的应用价值。
论文原文标题:《GOGGLE: GENERATIVE MODELLING FOR TABULAR DATA BY LEARNING RELATIONAL STRUCTURE》
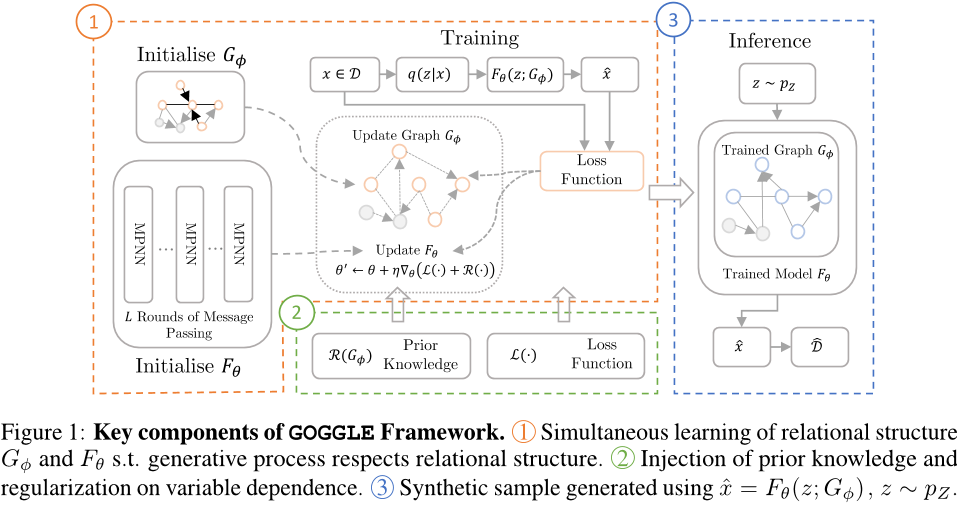
这篇论文介绍了一种名为GOGGLE的深度生成模型,用于学习和利用表格数据中的关系结构以更好地建模变量依赖,并通过引入正则化和先验知识来提高模型性能。与传统的完全连接层不同,该方法使用消息传递机制,能够捕捉稀疏、异构的关系结构。实验结果表明,该方法在生成真实样本文本方面表现良好,并且可以有效地应用于下游任务中。
!GOGGLE: GENERATIVE MODELLING FOR TABULAR DATA BY LEARNING RELATIONAL STRUCTURE
{kind=link}
论文方法
方法描述.本文提出了一种基于关系结构的生成模型——GOOGLE(Graph-guided Generative Modeling for Omitted Variable Leverage)。该模型利用学习到的关系结构来指导生成过程,并通过信息传播的方式处理依赖于其他变量的变量。具体来说,模型包括两个主要组件:可学习的关系结构和基于消息传递神经网络的生成模型。关系结构表示为一个加权无向图,其中节点是随机变量,边表示它们之间的依赖关系。生成模型使用消息传递机制在图上执行多轮信息传播,以确定每个变量的值。最后,模型将噪声向量作为输入,通过生成模型生成数据样本。
论文原文标题:《Local Differentially Private Heavy Hitter Detection in Data Streams with Bounded Memory》
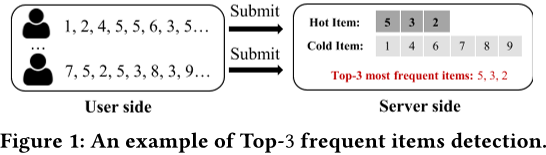
本文介绍了一种名为HG-LDP的新框架,旨在实现在有限内存空间内准确检测数据流中的前k个高频项,并提供严格的本地差分隐私保护。该框架解决了传统LDP技术在处理大数据集和内存限制时存在的“准确性、隐私性和内存效率”之间的不良权衡问题。通过设计新的LDP随机化方法,该框架能够有效地应对大规模项目域和内存空间受限的问题。实验结果表明,与基准方法相比,该框架能够在保证高精度的同时节省2300倍的内存空间。该框架的代码已经公开发布。
论文方法
方法描述。该论文提出了一种名为HG-LDP的框架,用于在数据流中跟踪Top-k项并保证用户隐私。该框架包含三个模块:随机化模块、存储模块和响应模块。随机化模块位于用户端,用于随机化用户的敏感数据;存储模块和响应模块位于服务器端,其中存储模块使用空间节省的数据结构。具体来说,使用HeavyGuardian(HG)数据结构来存储随机化的数据,并根据指数衰减策略更新计数。响应模块负责从HG中获取热门项目及其相应的计数,并将其映射到发布列表中,在发布之前对所有计数进行偏差校正。
论文原文标题:《Not Just Summing: The Identifier or Data Leakages of Private-Join-and-Compute and Its Improvement》
本篇论文探讨了在隐私保护下进行数据交互的问题,并针对Google提出的Private-Join-and-Compute库中存在的一些安全漏洞进行了分析和改进。具体来说,该库中的PIS协议和Reverse PIS协议在输入数据结构和处理过程中可能存在用户标识符泄露的风险。为了解决这些问题,本文提出了基于差分隐私技术的改进PIS协议,并对开源库进行了优化。通过使用Tamarin工具进行形式化分析和安全性证明,本文证明了改进后的PIS协议能够成功抵御已知攻击,并且不会带来明显的额外开销。