
在艾泽瑞亚大陆的魔法学院里,哋它亢已经度过了数月的时光。这段时间里,他不仅在魔法理论上打下了坚实的基础,更在艾琳的指导下,掌握了多种魔法的运用。然而,哋它亢并未满足于此,他一直在思考,如何将自己在地球上所学的计算机科学知识与这个世界的魔法相结合,创造出前所未有的魔法应用。
这天,哋它亢正在学院的图书馆里翻阅一本关于魔法阵的古籍。魔法阵,是艾泽瑞亚大陆上魔法师们用来聚集和释放魔法能量的一种图案或装置。它们通常被绘制在地面、墙壁或是特定的载体上,通过特定的咒语和仪式来激活,从而释放出强大的魔法力量。
哋它亢一边阅读着古籍,一边思考着魔法阵的工作原理。他注意到,传统的魔法阵设计往往依赖于魔法师的个人经验和直觉,缺乏一种系统化和精确化的方法。这让他想到了计算机科学中的算法和模型,如果能够将它们应用于魔法阵的设计中,或许能够大幅提升魔法阵的效率和稳定性。
【Byte Force 团队介绍】
在数字时代的大潮中,数据成为了新的石油,而保障数据的安全则成为了时代的使命。在这样的背景下,一群志同道合的青年才俊汇聚一堂,组成了“Byte Force”这支充满活力与创新精神的团队,致力于在大数据安全领域探索未知,挑战极限。我们是一支由浙江大学和华中科技大学的硕士、博士研究生共同组成的精英团队,成员们不仅具备深厚的学术背景,更拥有丰富的实践经验和敏锐的技术洞察力。我们的目标是在DataCon大数据安全分析竞赛中脱颖而出,为推动网络安全技术的发展贡献自己的力量。
团队编号:14259
团队特色
跨界融合:“Byte Force”团队成员来自不同的学科背景,这种多样性使得我们在面对复杂问题时能够从多个角度出发,综合运用各种知识和技能,找到最优解。 实战导向:我们深知理论与实践相结合的重要性。因此,在准备过程中,团队不仅深入学习相关领域的最新进展,还积极参与各类实践活动,如CTF比赛等,以增强实际操作能力。 持续创新:面对日新月异的技术环境,“Byte Force”始终保持开放的心态,鼓励成员不断探索新技术、新方法,力求在比赛中展现最前沿的安全防护理念。 合作共赢:我们坚信集体的力量大于个人。在整个备战期间,团队成员之间相互支持、密切配合,共同克服了无数困难,形成了强大的凝聚力。
【Byte Force 团队介绍】
在数字时代的大潮中,数据成为了新的石油,而保障数据的安全则成为了时代的使命。在这样的背景下,一群志同道合的青年才俊汇聚一堂,组成了“Byte Force”这支充满活力与创新精神的团队,致力于在大数据安全领域探索未知,挑战极限。我们是一支由浙江大学和华中科技大学的硕士、博士研究生共同组成的精英团队,成员们不仅具备深厚的学术背景,更拥有丰富的实践经验和敏锐的技术洞察力。我们的目标是在DataCon大数据安全分析竞赛中脱颖而出,为推动网络安全技术的发展贡献自己的力量。
团队编号:14259
团队特色
跨界融合:“Byte Force”团队成员来自不同的学科背景,这种多样性使得我们在面对复杂问题时能够从多个角度出发,综合运用各种知识和技能,找到最优解。 实战导向:我们深知理论与实践相结合的重要性。因此,在准备过程中,团队不仅深入学习相关领域的最新进展,还积极参与各类实践活动,如CTF比赛等,以增强实际操作能力。 持续创新:面对日新月异的技术环境,“Byte Force”始终保持开放的心态,鼓励成员不断探索新技术、新方法,力求在比赛中展现最前沿的安全防护理念。 合作共赢:我们坚信集体的力量大于个人。在整个备战期间,团队成员之间相互支持、密切配合,共同克服了无数困难,形成了强大的凝聚力。
在一个深夜,大二计算机科学与技术的学生哋它亢,正埋头于复杂的算法与数据结构之中,准备即将到来的期末考试。突然,一道耀眼的光芒从他眼前的电脑屏幕中迸发而出,将他整个包裹其中。当光芒消散时,哋它亢发现自己已经不在熟悉的实验室,而是站在一个陌生而充满奇幻色彩的异世界之中。
深夜,哋它亢独自坐在实验室的角落,键盘敲击声在寂静的空气中回荡。屏幕上的代码如同一串串神秘符号,正等待着他去解开其中的奥秘。作为大二计算机科学和技术专业的学生,哋它亢对编程充满了无尽的热爱。今天,他正准备解决一个困扰已久的算法难题,为此他已经连续工作了数个小时,双眼布满了血丝,但精神依然亢奋。
在一个深夜,大二计算机科学与技术的学生哋它亢,正埋头于复杂的算法与数据结构之中,准备即将到来的期末考试。突然,一道耀眼的光芒从他眼前的电脑屏幕中迸发而出,将他整个包裹其中。当光芒消散时,哋它亢发现自己已经不在熟悉的实验室,而是站在一个陌生而充满奇幻色彩的异世界之中。
当哋它亢再次睁开眼睛时,他发现自己正躺在一片陌生的森林中。阳光透过树叶的缝隙洒在他的脸上,带来一丝温暖而陌生的感觉。他挣扎着坐起身,环顾四周,发现自己置身于一个完全陌生的环境中。
他记得自己在实验室里工作到深夜,然后突然触电。但此刻,实验室的灯光、键盘和代码都已不复存在,取而代之的是茂密的树木、清新的空气和远处传来的奇异鸟鸣声。
在一个深夜,大二计算机科学与技术的学生哋它亢,正埋头于复杂的算法与数据结构之中,准备即将到来的期末考试。突然,一道耀眼的光芒从他眼前的电脑屏幕中迸发而出,将他整个包裹其中。当光芒消散时,哋它亢发现自己已经不在熟悉的实验室,而是站在一个陌生而充满奇幻色彩的异世界之中。
哋它亢在异世界的每一天都充满了新奇与挑战。自从他意外地在这个充满魔法与奇幻的世界醒来后,他的生活轨迹便彻底改变了。尽管起初他感到困惑和迷茫,但随着时间的推移,他开始逐渐适应这个新世界,并意识到,或许他的计算机科学背景能在这里找到意想不到的用武之地。
哋它亢醒来时,发现自己正躺在一片陌生的森林中。阳光透过密集的树冠,斑驳地洒在他的脸上,带来一丝丝温暖。他揉了揉眼睛,试图回忆起昨晚发生的事情,但脑海中只有一片模糊。只记得自己在实验室里忙碌着,突然之间,一股强烈的电流贯穿全身,然后他便失去了意识。
“这是哪里?”哋它亢坐起身来,环顾四周。眼前的景象与他所熟悉的现实世界截然不同。树木高耸入云,枝叶繁茂,空气中弥漫着一种他从未闻过的清新气息。远处,几声清脆的鸟鸣打破了森林的宁静,让他感受到一种前所未有的宁静与和谐。
他站起身来,拍了拍身上的尘土,开始探索这个新世界。他沿着一条蜿蜒的小径前行,小径两旁是各种各样的野花和奇异的植物,有的开着绚烂的花朵,有的则散发着淡淡的荧光。这些景象让他感到既惊奇又兴奋,仿佛自己踏入了一个梦幻般的仙境。

在数据隐私日益重要的今天,如何在保护数据隐私的前提下进行数据交集操作成为了学术界和工业界共同关注的焦点。其中,两方私有集合交集(Private Set Intersection, PSI)作为一种重要的密码学应用,允许两个参与方在不知道对方完整集合的情况下,共同计算出双方集合的交集。本文将深入解读由梁之源等人撰写的论文《Benchmark of Two-party Private Set Intersection》,探讨PSI的基本概念、技术原理、应用场景以及最新进展。
一、PSI的基本概念
PSI的核心目标是允许两个参与方(通常称为发送方和接收方)在保护各自数据隐私的前提下,共同计算出它们集合的交集。在这个过程中,双方均不会了解到交集之外的其他信息。这种隐私保护特性使得PSI在许多场景中都具有广泛的应用价值。
原论文标题:《Chatbots in science: What can ChatGPT do for you?》
hatGPT 于 2022 年 11 月推出,震惊了世界。由位于加利福尼亚州旧金山的 OpenAI 创建的人工智能 (AI) 聊天机器人由大型语言模型 ( LLM ) 提供支持,并根据互联网上发布的大部分文本进行训练,使通过提供能够回答复杂问题、撰写复杂论文和生成源代码的基于对话的界面,可以广泛获取自然语言处理的最新进展。一个明显的问题是:这一工具如何改进科学?
要有效地使用聊天机器人,您需要良好的提示。这听起来似乎是显而易见的,但当该工具无法回答一个不清楚的问题时,我的一些同事仍然会感到沮丧并放弃。这是可以理解的:公众一直被这些模型“智能”的想法轰炸,因此认为他们应该理解你提出的任何问题是有道理的。但事实并非如此,这就是为什么即时工程已成为该领域快速发展的学科。
论文原文标题:《GOGGLE: GENERATIVE MODELLING FOR TABULAR DATA BY LEARNING RELATIONAL STRUCTURE》
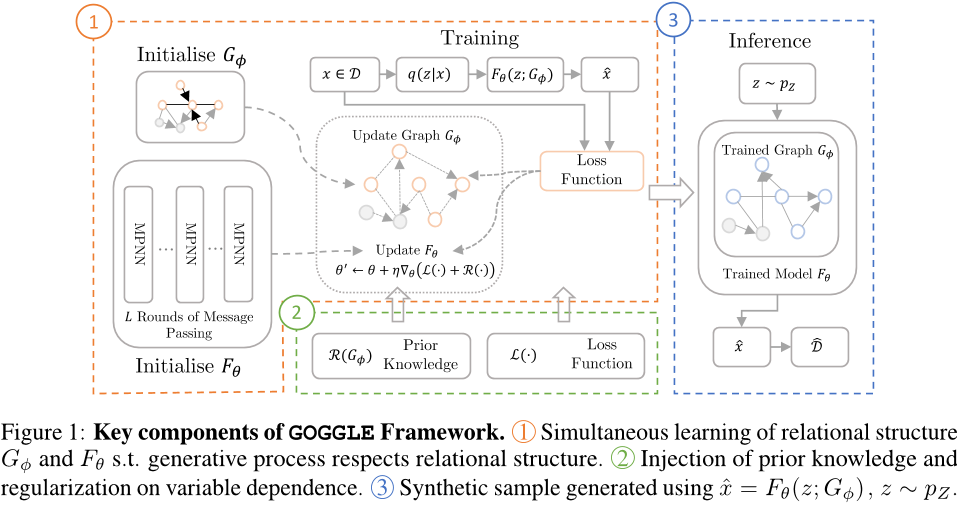
这篇论文介绍了一种名为GOGGLE的深度生成模型,用于学习和利用表格数据中的关系结构以更好地建模变量依赖,并通过引入正则化和先验知识来提高模型性能。与传统的完全连接层不同,该方法使用消息传递机制,能够捕捉稀疏、异构的关系结构。实验结果表明,该方法在生成真实样本文本方面表现良好,并且可以有效地应用于下游任务中。
!GOGGLE: GENERATIVE MODELLING FOR TABULAR DATA BY LEARNING RELATIONAL STRUCTURE
{kind=link}
论文方法
方法描述.本文提出了一种基于关系结构的生成模型——GOOGLE(Graph-guided Generative Modeling for Omitted Variable Leverage)。该模型利用学习到的关系结构来指导生成过程,并通过信息传播的方式处理依赖于其他变量的变量。具体来说,模型包括两个主要组件:可学习的关系结构和基于消息传递神经网络的生成模型。关系结构表示为一个加权无向图,其中节点是随机变量,边表示它们之间的依赖关系。生成模型使用消息传递机制在图上执行多轮信息传播,以确定每个变量的值。最后,模型将噪声向量作为输入,通过生成模型生成数据样本。
论文原文标题:《Local Differentially Private Heavy Hitter Detection in Data Streams with Bounded Memory》
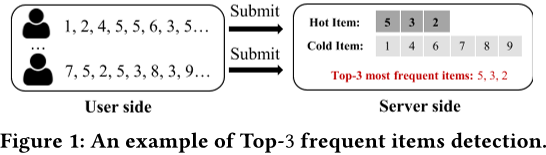
本文介绍了一种名为HG-LDP的新框架,旨在实现在有限内存空间内准确检测数据流中的前k个高频项,并提供严格的本地差分隐私保护。该框架解决了传统LDP技术在处理大数据集和内存限制时存在的“准确性、隐私性和内存效率”之间的不良权衡问题。通过设计新的LDP随机化方法,该框架能够有效地应对大规模项目域和内存空间受限的问题。实验结果表明,与基准方法相比,该框架能够在保证高精度的同时节省2300倍的内存空间。该框架的代码已经公开发布。
论文方法
方法描述。该论文提出了一种名为HG-LDP的框架,用于在数据流中跟踪Top-k项并保证用户隐私。该框架包含三个模块:随机化模块、存储模块和响应模块。随机化模块位于用户端,用于随机化用户的敏感数据;存储模块和响应模块位于服务器端,其中存储模块使用空间节省的数据结构。具体来说,使用HeavyGuardian(HG)数据结构来存储随机化的数据,并根据指数衰减策略更新计数。响应模块负责从HG中获取热门项目及其相应的计数,并将其映射到发布列表中,在发布之前对所有计数进行偏差校正。
论文原文标题:《Not Just Summing: The Identifier or Data Leakages of Private-Join-and-Compute and Its Improvement》
本篇论文探讨了在隐私保护下进行数据交互的问题,并针对Google提出的Private-Join-and-Compute库中存在的一些安全漏洞进行了分析和改进。具体来说,该库中的PIS协议和Reverse PIS协议在输入数据结构和处理过程中可能存在用户标识符泄露的风险。为了解决这些问题,本文提出了基于差分隐私技术的改进PIS协议,并对开源库进行了优化。通过使用Tamarin工具进行形式化分析和安全性证明,本文证明了改进后的PIS协议能够成功抵御已知攻击,并且不会带来明显的额外开销。
随机数的文献综述
一、引言
随机数,作为数学和计算机科学中的重要概念,具有广泛的应用价值。从模拟实验、加密安全,到游戏算法、统计学等领域,随机数都发挥着关键作用。本文将系统地回顾随机数的发展历程,定义描述,以及软件和硬件实现随机数的不同方案。
二、随机数的定义与描述
随机数是一个数值或序列,其出现与否不受确定性的规则所控制。在数学上,随机数满足某些统计规律,但不能预测其具体值。按照性质,随机数可以分为真随机数和伪随机数。真随机数由物理现象产生,如掷骰子或放射性衰变,而伪随机数则由确定的算法生成。
三、随机数的发展历程
早在古希腊时期,数学家就开始研究随机现象,但真正的随机数生成器直到20世纪才出现。随着计算机科学的发展,随机数生成算法也不断进步,从线性同余生成器到更复杂的算法如梅森旋转体和混沌理论方法。