论文原文标题:《GOGGLE: GENERATIVE MODELLING FOR TABULAR DATA BY LEARNING RELATIONAL STRUCTURE》
这篇论文介绍了一种名为GOGGLE的深度生成模型,用于学习和利用表格数据中的关系结构以更好地建模变量依赖,并通过引入正则化和先验知识来提高模型性能。与传统的完全连接层不同,该方法使用消息传递机制,能够捕捉稀疏、异构的关系结构。实验结果表明,该方法在生成真实样本文本方面表现良好,并且可以有效地应用于下游任务中。
!GOGGLE: GENERATIVE MODELLING FOR TABULAR DATA BY LEARNING RELATIONAL STRUCTURE
{kind=link}
论文方法
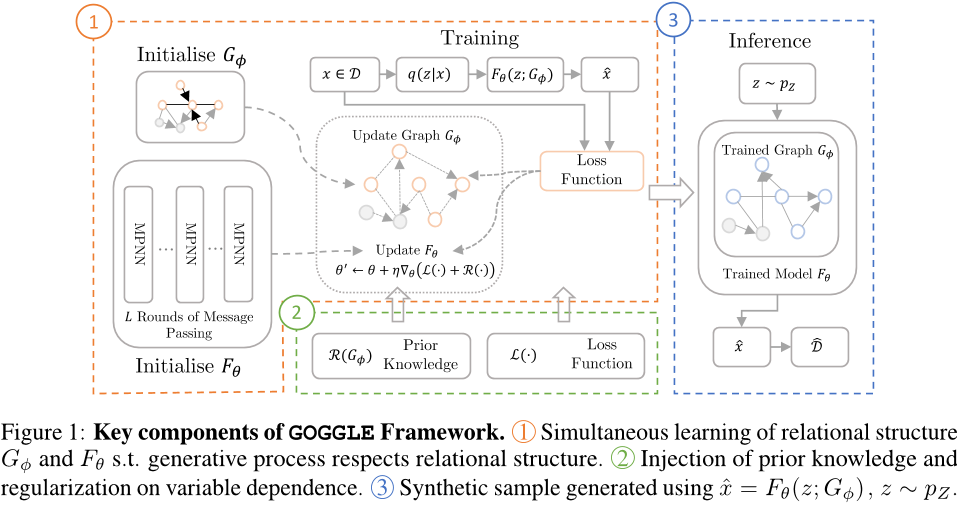
方法描述.本文提出了一种基于关系结构的生成模型——GOOGLE(Graph-guided Generative Modeling for Omitted Variable Leverage)。该模型利用学习到的关系结构来指导生成过程,并通过信息传播的方式处理依赖于其他变量的变量。具体来说,模型包括两个主要组件:可学习的关系结构和基于消息传递神经网络的生成模型。关系结构表示为一个加权无向图,其中节点是随机变量,边表示它们之间的依赖关系。生成模型使用消息传递机制在图上执行多轮信息传播,以确定每个变量的值。最后,模型将噪声向量作为输入,通过生成模型生成数据样本。
方法改进.与传统的生成模型相比,GOOGLE的主要改进在于引入了关系结构的概念。传统模型通常采用全连接的MLP来建模变量之间的依赖关系,而GOOGLE则利用学习到的关系结构来更好地捕捉异质变量之间的关系。此外,GOOGLE还设计了一个灵活的消息传递神经网络来处理循环依赖关系和降低计算负担。
解决的问题.GOOGLE的目标是在没有先验知识的情况下学习数据中的潜在关系结构,并在此基础上生成新的数据样本。这种方法可以应用于各种类型的生成任务,例如图像生成、文本生成等。同时,GOOGLE还可以用于数据增强,即根据给定条件生成合成数据。总之,GOOGLE提供了一种有效的方法来捕捉复杂数据集中的依赖关系并生成高质量的数据样本。
论文实验
本文主要介绍了基于关系的归纳偏见(relational inductive biases)在生成模型中的应用,并通过多个对比实验来验证其效果。具体来说,本文进行了以下五个方面的实验:
合成数据质量评估:通过对三个指标(质量、检测和效用)的量化评估,比较了作者提出的GOGGLE模型与基准模型在合成数据质量上的表现。结果表明,GOGGLE模型在所有指标上都表现出更好的性能,特别是在小规模数据集上的表现更为突出。
先验知识利用:该实验探究了将部分先验知识引入到模型中是否能够提高生成性能。作者采用了三种不同的先验知识设置,并对ECOLI和MAGIC两个数据集进行了实验。结果显示,在不同数据量下,引入先验知识都能够显著提高生成性能,特别是当训练样本较少时。
关系结构学习动态分析:该实验旨在研究关系结构学习和生成模型之间的相互作用以及关系结构对性能提升的影响。作者设计了几种不同的关系结构学习方法,并对其性能进行了比较。结果表明,联合学习关系结构和函数关系是实现良好性能的关键因素。
增量式数据增强:该实验是对另一种使用关系结构进行数据增强的方法的评估。作者通过在UCI数据集上进行实验,比较了GOGGLE模型和其他方法在增量式数据增强任务上的表现。结果显示,GOGGLE模型在所有数据集上都表现出更好的性能。
对比实验结果综合评估:该实验综合考虑了前面四个实验的结果,并对不同数据集和方法的表现进行了排名。结果表明,GOGGLE模型在大多数情况下都表现出最佳的性能。
总的来说,本文通过多个实验验证了基于关系的归纳偏见在生成模型中的有效性,并证明了GOGGLE模型在合成数据质量和增量式数据增强等任务中具有优越的性能。
论文总结
文章优点
- 本文提出了一种新的表格数据生成模型GOGGLE,该模型能够通过消息传递机制同时学习关系结构和函数关系,以更好地捕捉稀疏性和异质性关系。该模型使用关系结构来指导生成过程,可以将先验知识和正则化应用于变量依赖性,从而提高模型性能。此外,作者还提出了针对更高级别表格数据(如基因组学)扩展关系结构学习的方法。
方法创新点
- 本文的主要贡献是提出了一种基于图学习的生成模型GOGGLE,该模型在表格数据上实现了更好的性能。与传统的多层感知器相比,GOGGLE能够更好地利用关系结构,并且可以使用正则化技术减少过拟合问题。此外,该模型还可以集成领域专家的知识,从而进一步提高模型性能。
未来展望
- 尽管本文提出的GOGGLE已经在表格数据生成方面取得了很好的效果,但仍然存在一些挑战需要解决。例如,在高维表格数据上的应用,如何有效地扩展关系结构学习等问题。因此,未来的研究方向包括改进模型的可扩展性和适应性,以及探索更多的应用场景。