原标题:《CTAB-GAN+: enhancing tabular data synthesis》
发表平台:Frontiers in Big Data
摘要
本文介绍了一种新的条件表格生成对抗网络(CTAB-GAN+),旨在生成高质量的合成数据,同时提供严格的隐私保护。CTAB-GAN+通过添加下游损失来提高合成数据的效用,使用Wasserstein损失和梯度惩罚来改善训练收敛性,并引入了针对混合连续-分类变量和不平衡数据的新编码器。此外,CTAB-GAN+使用差分隐私随机梯度下降(DP-SGD)进行训练,以确保隐私保护。实验结果表明,CTAB-GAN+在多个数据集和学习任务中,能够在给定的隐私预算下,将机器学习效用(如F1分数)提高至少21.9%。
解决的主要问题
本文主要研究领域为表格数据合成和差分隐私保护。随着大数据时代的到来,合成数据在数据分析和模型训练中发挥着重要作用,但同时也面临着隐私泄露的风险。现有的生成对抗网络(GAN)在生成高质量合成数据方面取得了显著进展,但在隐私保护方面存在不足。本文旨在通过改进GAN模型,同时提高合成数据的质量和隐私保护水平,解决这一问题。
主要方法和技术
CTAB-GAN+的主要方法和技术包括:
- 下游损失:CTAB-GAN+引入了下游损失,即在训练过程中加入分类或回归任务的损失函数,以提高生成数据在实际任务中的效用。
- Wasserstein损失和梯度惩罚:使用Wasserstein损失(WGAN)结合梯度惩罚(WGAN-GP),以改善模型训练的稳定性和收敛性。
- 新型编码器:针对混合连续-分类变量和不平衡数据,设计了新的编码器,以更好地处理这些类型的数据。
- 差分隐私随机梯度下降(DP-SGD):在训练生成器和辅助模型时使用DP-SGD,以确保生成过程中的隐私保护。
- 子采样技术:通过子采样技术减少隐私成本,即在训练模型时使用较小的子集代替整个数据集。
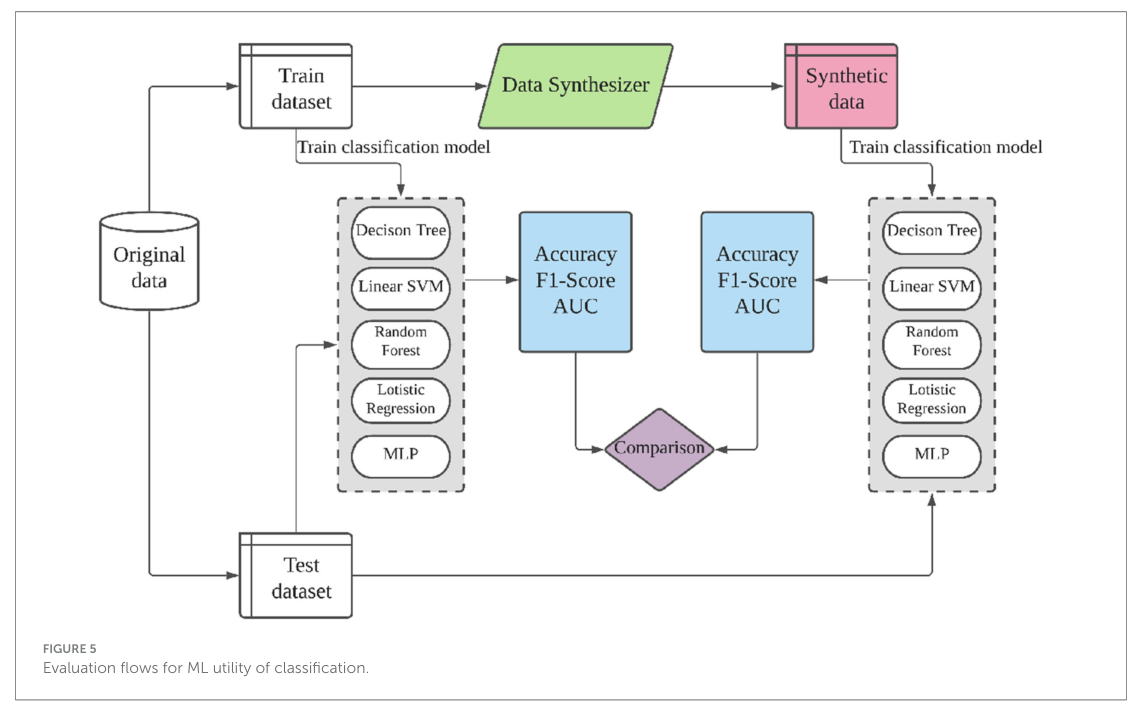
实验设置与实验结果
实验设置:
- 数据集:实验使用了七个广泛使用的机器学习数据集,包括Adult、Covertype、Credit、Intrusion、Loan、Insurance和King。
- 基线方法:与九种最先进的表格数据生成算法进行了比较,包括IT-GAN、CTGAN、TVAE、TableGAN、CWGAN和MedGAN(无隐私保护设置),以及PATE-GAN、DP-WGAN和GS-WGAN(有隐私保护设置)。
- 评价指标:使用机器学习效用(如准确率、AUC、F1分数)和统计相似性作为评价指标。
实验结果:
- 无隐私保护设置:CTAB-GAN+在所有基线方法上平均提高了至少33.5%的准确率和56.4%的AUC。
- 有隐私保护设置:在相同的隐私预算(ε=1和ε=100)下,CTAB-GAN+在F1分数上分别平均提高了至少7.8%和21.9%。
总结
本文的重要贡献在于提出了一种新的条件表格生成对抗网络CTAB-GAN+,通过多种技术创新,显著提高了合成数据的质量和隐私保护水平。具体而言,CTAB-GAN+通过引入下游损失、使用Wasserstein损失和梯度惩罚、设计新型编码器以及采用差分隐私随机梯度下降等方法,有效解决了现有GAN模型在生成高质量合成数据时的隐私保护问题。实验结果表明,CTAB-GAN+在多个数据集和学习任务中表现出色,能够在给定的隐私预算下显著提高机器学习效用。这些成果为合成数据在实际应用中的安全性提供了有力支持。